
Node.js is a server-side JavaScript runtime that uses an event-driven, non-blocking input-output (I/O) style. It’s widely recognized for construction rapid and scalable web apps. It moreover has a large staff and a rich library of modules that simplify quite a lot of tasks and processes.
Clustering enhances the potency of Node.js packages by the use of enabling them to run on multiple processes. The program permits them to use the entire possible of a multi-core device.
This newsletter takes an entire take a look at clustering in Node.js and how it affects the potency of an device.
What’s clustering?
By the use of default, Node.js programs run on a single thread. This single-threaded nature means Node.js can’t use all the cores in a multi-core device — which most tactics this present day are.
Node.js can however maintain multiple requests at the same time as by the use of leveraging non-blocking I/O operations and asynchronous programming techniques.
Then again, heavy computational tasks can block the improvement loop and cause the applying to turn out to be unresponsive. Consequently, Node.js comes with a neighborhood cluster module — irrespective of its single-threaded nature — to get pleasure from the entire processing power of a multi-core device.
Working multiple processes leverages the processing power of multiple central processing unit (CPU) cores to allow parallel processing, cut back response events, and increase throughput. This, in turn, improves the potency and scalability of Node.js programs.
How does clustering art work?
The Node.js cluster module we could in a Node.js device to create a cluster of at the same time as running child processes, each coping with a portion of the applying’s workload.
When initializing the cluster module, the applying creates the primary process, which then forks child processes into worker processes. The principle process acts as a load balancer, distributing the workload to the worker processes while each worker process listens for incoming requests.
The Node.js cluster module has two methods of distributing incoming connections.
- The round-robin means — The principle process listens on a port, accepts new connections and lightly distributes the workload to make sure no process is overloaded. That’s the default manner on all working tactics apart from House home windows.
- The second manner — The principle process creates the listen socket and sends it to “” workers, which accept incoming connections right away.
Theoretically, the second manner — which is additional tricky — will have to provide a better potency. Alternatively in practice, the distribution of the connections could also be very unbalanced. The Node.js documentation mentions that 70% of all connections after all finally end up in merely two processes out of 8.
Simple tips on how to cluster your Node.js programs
Now, let’s learn concerning the penalties of clustering in a Node.js device. This tutorial uses an Particular device that intentionally runs a heavy computational procedure to block the improvement loop.
First, run this device without clustering. Then, record the potency with a benchmarking device. Next, clustering is performed throughout the device, and benchmarking is repeated. After all, review the results to see how clustering improves your device’s potency.
Getting started
To snatch this tutorial, you’ll have to be familiar with Node.js and Specific. To prepare your Specific server:
- Get began by the use of growing the undertaking.
mkdir cluster-tutorial - Navigate to the applying list and create two files, no-cluster.js and cluster.js, by the use of running the command beneath:
cd cluster-tutorial && touch no-cluster.js && touch cluster.js - Initialize NPM in your undertaking:
npm init -y - After all, arrange Particular by the use of running the command beneath:
npm arrange express
Creating a non-clustered device
In your no-cluster.js report, add the code block beneath:
const express = require("express");
const PORT = 3000;
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/sluggish", (req, res) => {
//Get began timer
console.time("sluggish");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});The code block above creates an express server that runs on port 3000. The server has two routes, a root (/) course and a /sluggish course. The basis course sends a response to the buyer with the message: “Response from server.”
Then again, the /sluggish course intentionally does some heavy computation to block the improvement loop. This course starts a timer and then fills an array with 100,000 random numbers the use of a for loop.
Then, the use of another for loop, it squares each amount throughout the generated array and gives them. The timer ends when this is complete, and the server responds with the results.
Get began your server by the use of running the command beneath:
node no-cluster.jsThen make a GET request to localhost:3000/sluggish.
Throughout this time, in case you attempt to make any other requests in your server — comparable to to the basis course (/) — the responses are sluggish for the reason that /sluggish course is blocking the improvement loop.
Creating a clustered device
Spawn child processes the use of the cluster module to make sure your device doesn’t turn out to be unresponsive and stall subsequent requests everywhere heavy computational tasks.
Every child process runs its instance loop and shares the server port with the father or mother process, allowing upper use of available resources.
First, import the Node.js cluster and os module into your cluster.js report. The cluster module we could in for the advent of child processes to distribute the workload right through multiple CPU cores.
The os module provides information about your pc’s working device. You want this module to retrieve the choice of cores available in your device and just be sure you don’t create additional child processes than cores in your device.
Add the code block beneath to import the ones modules and retrieve the choice of cores in your device:
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;Next, add the code block beneath in your cluster.js report:
if (cluster.isMaster) {
console.log(`Take hold of ${process.pid} is working`);
console.log(`This device has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Trade the useless worker
console.log("Starting a brand spanking new worker");
cluster.fork();
});
}The code block above tests whether or not or no longer the existing process is the primary or worker process. If true, the code block spawns child processes in keeping with the choice of cores in your device. Next, it listens for the pass out instance on the processes and replaces them by the use of spawning new processes.
After all, wrap all the similar express excellent judgment in an else block. Your finished cluster.js report will have to be similar to the code block beneath.
//cluster.js
const express = require("express");
const PORT = 3000;
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;
if (cluster.isMaster) {
console.log(`Take hold of ${process.pid} is working`);
console.log(`This device has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Trade the useless worker
console.log("Starting a brand spanking new worker");
cluster.fork();
});
} else {
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/sluggish", (req, res) => {
console.time("sluggish");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});
}After imposing clustering, multiple processes will maintain requests. This means that your device remains responsive even everywhere a heavy computational procedure.
Simple tips on how to benchmark potency the use of loadtest
To as it should be display and display the effects of clustering in a Node.js device, use the npm package deal deal loadtest to check the potency of your device previous to and after clustering.
Run the command beneath to position in loadtest globally:
npm arrange -g loadtestThe loadtest package deal deal runs a load take a look at on a specified HTTP/WebSockets URL.
Next, get began up your no-cluster.js report on a terminal instance. Then, open another terminal instance and run the load take a look at beneath:
loadtest http://localhost:3000/sluggish -n 100 -c 10The command above sends 100 requests with a concurrency of 10 in your unclustered app. Working this command produces the results beneath:
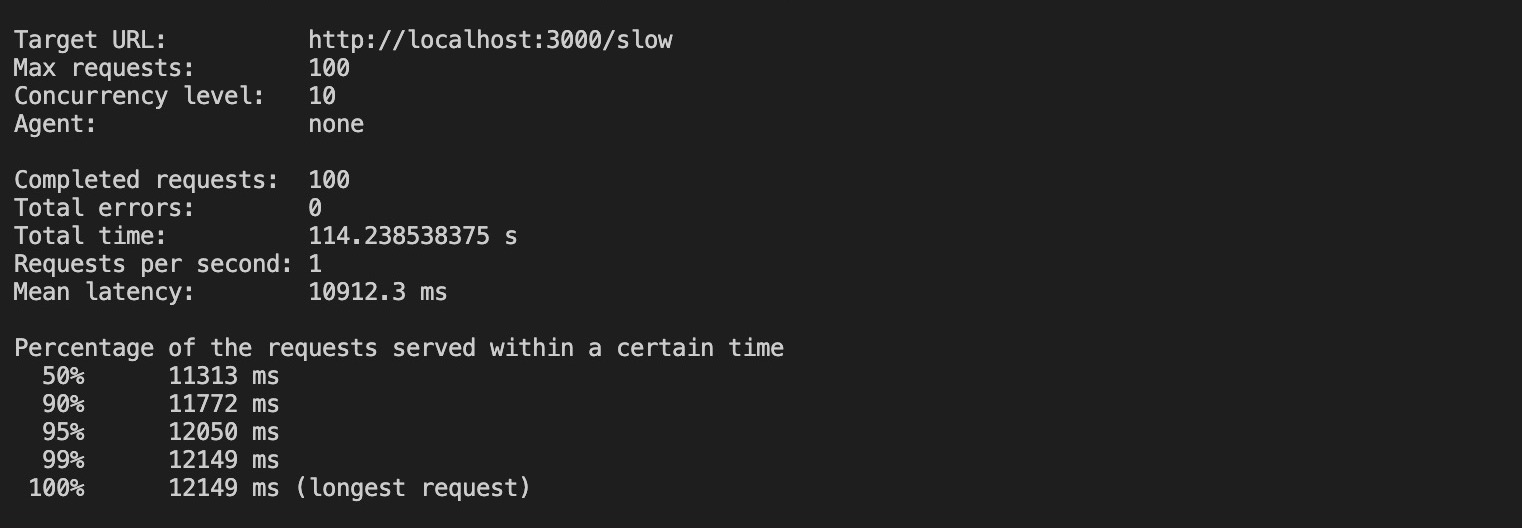
Consistent with the results, it took more or less 100 seconds to complete all the requests without clustering, and some of the extended request took up to 12 seconds to complete.
Results will vary in keeping with your device.
Next, save you running the no-cluster.js report and get began up your cluster.js report on a terminal instance. Then, open another terminal instance and run this load take a look at:
loadtest http://localhost:3000/sluggish -n 100 -c 10The command above will send 100 requests with a concurrency 10 in your clustered app.
Working this command produces the results beneath:
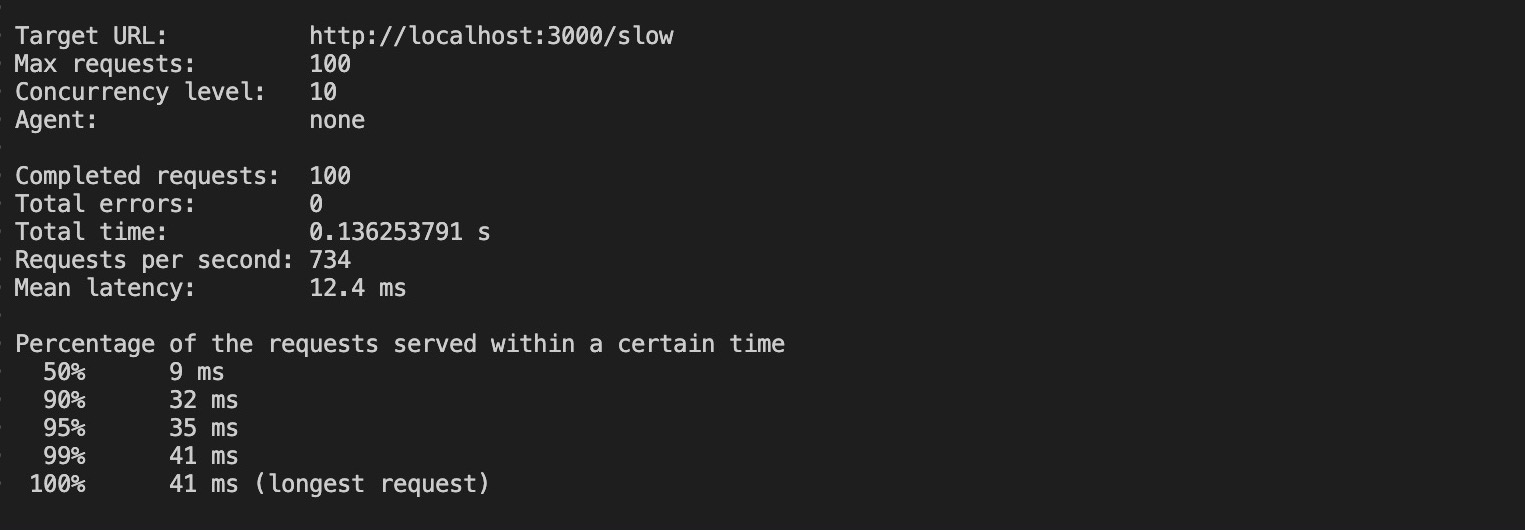
With clustering, the requests took 0.13 seconds (136 ms) to complete its requests, a huge decrease from the 100 seconds the unclustered app required. Additionally, some of the extended request on the clustered app took 41 ms to complete.
The ones results display that imposing clustering significantly improves your device’s potency. Bear in mind that you’ll be able to use process regulate instrument like PM2 to control your clustering in production environments.
The use of Node.js with Kinsta’s Application Web web hosting
Kinsta is a internet web hosting company that makes it easy to deploy your Node.js packages. Its internet web hosting platform is built on the Google Cloud Platform, which provides a reliable infrastructure designed to maintain best guests and improve difficult programs. Ultimately, this improves the potency of Node.js programs.
Kinsta supplies quite a lot of choices for Node.js deployments, comparable to inner database connections, Cloudflare integration, GitHub deployments, and Google C2 Machines.
The ones choices make it easy to deploy and prepare Node.js programs and streamline the improvement process.
To deploy your Node.js device to Kinsta’s Utility Internet hosting, it’s crucial to push your software’s code and recordsdata in your decided on Git provider (Bitbucket, GitHub, or GitLab).
Once your repository is able, practice the ones steps to deploy your Particular device to Kinsta:
- Log in or create an account to view your MyKinsta dashboard.
- Authorize Kinsta in conjunction with your Git provider.
- Click on on Methods on the left sidebar, then click on on Add device.
- Select the repository and the dep. you wish to have to deploy from.
- Assign a novel identify in your app and select a Data center location.
- Configure your assemble setting next. Select the Standard assemble device config with the really helpful Nixpacks selection for this demo.
- Use all default configurations and then click on on Create device.
Summary
Clustering in Node.js allows the advent of multiple worker processes to distribute the workload, improving the potency and scalability of Node.js programs. As it should be imposing clustering is crucial to achieving this technique’s entire possible.
Designing the construction, managing helpful useful resource allocation, and minimizing neighborhood latency are important components when imposing clustering in Node.js. The importance and complexity of this implementation are why process managers like PM2 will have to be used in production environments.
What is your thought to be Node.js clustering? Have you ever ever used it previous to? Share throughout the statement section!
The publish Why Node.js clustering is vital for optimized packages seemed first on Kinsta®.
Contents
- 1 What’s clustering?
- 2 Simple tips on how to cluster your Node.js programs
- 3 Simple tips on how to benchmark potency the use of loadtest
- 4 Summary
- 5 5 Advertising Mavens Are expecting The Most sensible Developments We’re going to See in 2025
- 6 WordPress Web hosting With Limitless Garage And Bandwidth / Wyoming’s Wild…
- 7 How you can Taste the Divi Name to Motion Module (3 Examples!)

0 Comments