
If you happen to prepare many WordPress web sites, you’re maximum undoubtedly always on the lookout for ways to simplify and boost up your workflows.
Now, imagine this: with a single command in your terminal, you’ll have the ability to prompt information backups for all of your web sites, even if you’re managing dozens of them. That’s the ability of blending shell scripts with the Kinsta API.
This knowledge teaches you learn to use shell scripts to prepare custom designed directions that make managing your web sites further atmosphere pleasant.
Prerequisites
Previous than we start, proper right here’s what you need:
- A terminal: All fashionable operating ways come with terminal software, so that you’ll have the ability to get began scripting right kind out of the sphere.
- An IDE or text editor: Use a tool you’re comfortable with, whether or not or now not it’s VS Code, Elegant Text, or most likely a lightweight editor like Nano for quick terminal edits.
- A Kinsta API key: This is essential for interacting with the Kinsta API. To generate yours:
- Log in for your MyKinsta dashboard.
- Transfer to Your Name > Company Settings > API Keys.
- Click on on Create API Key and save it securely.
curlandjq: The most important for making API requests and coping with JSON data. Take a look at they’re installed, or arrange them.- Elementary programming familiarity: You don’t need to be a professional, alternatively understanding programming basics and shell scripting syntax will be helpful.
Writing your first script
Rising your first shell script to engage with the Kinsta API is more practical than you might think. Let’s get began with a simple script that lists all of the WordPress web sites managed beneath your Kinsta account.
Step 1: Prepare your environment
Get started by the use of creating a folder to your problem and a brand spanking new script report. The .sh extension is used for shell scripts. For example, you’ll have the ability to create a folder, navigate to it, and create and open a script report in VS Code using the ones directions:
mkdir my-first-shell-scripts
cd my-first-shell-scripts
touch script.sh
code script.shStep 2: Define your environment variables
To stick your API key protected, store it in a .env report instead of hardcoding it into the script. This allows you to add the .env report to .gitignore, combating it from being pushed to type control.
On your .env report, add:
API_KEY=your_kinsta_api_keyNext, pull the API key from the .env report for your script by the use of together with the following to the best of your script:
#!/bin/bash
provide .envThe #!/bin/bash shebang promises the script runs using Bash, while provide .env imports the environment variables.
Step 3: Write the API request
First, store your company ID (found in MyKinsta beneath Company Settings > Billing Details) in a variable:
COMPANY_ID=""Next, add the curl command to make a GET request to the /web sites endpoint, passing the company ID as a query parameter. Use jq to structure the output for readability:
curl -s -X GET
"https://api.kinsta.com/v2/web sites?company=$COMPANY_ID"
-H "Authorization: Bearer $API_KEY"
-H "Content material material-Type: software/json" | jqThis request retrieves details about all web sites similar in conjunction with your company, in conjunction with their IDs, names, and statuses.
Step 4: Make the script executable
Save the script and make it executable by the use of operating:
chmod +x script.shStep 5: Run the script
Execute the script to see a formatted report of your web sites:
./list_sites.shWhen you run the script, you’ll get a response similar to this:
{
"company": {
"web sites": [
{
"id": "a8f39e7e-d9cf-4bb4-9006-ddeda7d8b3af",
"name": "bitbuckettest",
"display_name": "bitbucket-test",
"status": "live",
"site_labels": []
},
{
"identity": "277b92f8-4014-45f7-a4d6-caba8f9f153f",
"name": "duketest",
"display_name": "zivas Signature",
"status": "are living",
"site_labels": []
}
]
}
}While this works, let’s fortify it by the use of setting up a function to fetch and structure the site details for easier readability.
Step 6: Refactor with a function
Trade the curl request with a reusable function to deal with fetching and formatting the site report:
list_sites() "(.display_name) ((.name)) - Status: (.status)"'
# Run the function
list_sitesWhen you execute the script another time, you’ll get neatly formatted output:
Fetching all web sites for company ID: b383b4c-****-****-a47f-83999c5d2...
Company Internet sites:
--------------
bitbucket-test (bitbuckettest) - Status: are living
zivas Signature (duketest) - Status: are livingWith this script, you’ve taken your first step in opposition to using shell scripts and the Kinsta API for automating WordPress site regulate. Throughout the next sections, we find rising further sophisticated scripts to engage with the API in powerful ways.
Difficult use case 1: Rising backups
Rising backups is a an important facet of internet web page regulate. They are going to mean you can restore your site in case of sudden issues. With the Kinsta API and shell scripts, this process can be automatic, saving time and effort.
In this section, we create backups and handle Kinsta’s limit of 5 information backups consistent with environment. To deal with this, we’ll enforce a process to:
- Take a look at the existing number of information backups.
- Decide and delete the oldest backup (with client confirmation) if the limit is reached.
- Proceed to create a brand spanking new backup.
Let’s get into the details.
The backup workflow
To create backups using the Kinsta API, you’ll use the next endpoint:
POST /web sites/environments/{env_id}/manual-backupsThis requires:
- Environment ID: Identifies the environment (like staging or production) where the backup will be created.
- Backup Tag: A label to identify the backup (now not mandatory).
Manually retrieving the environment ID and dealing a command like backup can be cumbersome. Instead, we’ll assemble a user-friendly script where you simply specify the site name, and the script will:
- Fetch the report of environments for the site.
- Suggested you to choose the environment to once more up.
- Deal with the backup creation process.
Reusable functions for clean code
To stick our script modular and reusable, we’ll define functions for specific tasks. Let’s pass throughout the setup step by step.
1. Prepare base variables
You’ll eliminate the main script you created or create a brand spanking new script report for this. Get began by the use of citing the ground Kinsta API URL and your company ID inside the script:
BASE_URL="https://api.kinsta.com/v2"
COMPANY_ID=""The ones variables will mean you can collect API endpoints dynamically right through the script.
2. Fetch all web sites
Define a function to fetch the report of all company web sites. This allows you to retrieve details about each site later.
get_sites_list() {
API_URL="$BASE_URL/web sites?company=$COMPANY_ID"
echo "Fetching all web sites for company ID: $COMPANY_ID..."
RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content material material-Type: software/json")
# Take a look at for errors
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API."
move out 1
fi
echo "$RESPONSE"
}You’ll perceive this function returns an unformatted response from the API. To get a formatted response. You’ll add each different function to deal with that (even supposing that isn’t our fear in this section):
list_sites() {
RESPONSE=$(get_sites_list)
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API while fetching web sites."
move out 1
fi
echo "Company Internet sites:"
echo "--------------"
# Clean the RESPONSE previous to passing it to jq
CLEAN_RESPONSE=$(echo "$RESPONSE" | tr -d 'r' | sed 's/^[^ jq -r '.corporate.websites[] Calling the list_sites function displays your web sites as confirmed earlier. The principle serve as, however, is to get admission to each site and its ID, allowing you to retrieve detailed information about each site.
3. Fetch site details
To fetch details about a decided on site, use the following function, which retrieves the site ID according to the site name and fetches additional details, like environments:
get_site_details_by_name() {
SITE_NAME=$1
if [ -z "$SITE_NAME" ]; then
echo "Error: No site name provided. Usage: $0 details-name "
return 1
fi
RESPONSE=$(get_sites_list)
echo "Looking for site with name: $SITE_NAME..."
# Clean the RESPONSE previous to parsing
CLEAN_RESPONSE=$(echo "$RESPONSE" | tr -d 'r' | sed 's/^[^ choose(.call == $SITE_NAME) The serve as above filters the website the usage of the website call after which retrieves further information about the website the usage of the /websites/ endpoint. Those particulars come with the website’s environments, which is what we want to set off backups.
Growing backups
Now that you just’ve arrange reusable purposes to fetch website particulars and record environments, you’ll be able to focal point on automating the method of making backups. The function is to run a easy command with simply the website call after which interactively make a selection the surroundings to again up.
Get started by way of making a serve as (we’re naming it trigger_manual_backup). Throughout the serve as, outline two variables: the primary to simply accept the website call as enter and the second one to set a default tag (default-backup) for the backup. This default tag shall be carried out until you select to specify a customized tag later.
trigger_manual_backup() {
SITE_NAME=$1
DEFAULT_TAG="default-backup"
# Make sure that a website call is equipped
if [ -z "$SITE_NAME" ]; then
echo "Error: Internet web page name is wanted."
echo "Usage: $0 trigger-backup "
return 1
fi
# Add the code proper right here
}This SITE_NAME is the identifier for the site you want to regulate. You moreover prepare a scenario so the script exits with an error message if the identifier isn’t provided. This promises the script doesn’t proceed without the necessary input, combating potential API errors.
Next, use the reusable get_site_details_by_name function to fetch detailed information about the site, in conjunction with its environments. The response is then cleaned to remove any sudden formatting issues that can get up right through processing.
SITE_RESPONSE=$(get_site_details_by_name "$SITE_NAME")
if [ $? -ne 0 ]; then
echo "Error: Didn't fetch site details for site "$SITE_NAME"."
return 1
fi
CLEAN_RESPONSE=$(echo "$SITE_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Once now we have the site details, the script beneath extracts all available environments and displays them in a readable structure. That is serving to you visualize which environments are attached to the site.
The script then turns on you to make a choice an environment by the use of its name. This interactive step makes the process user-friendly by the use of eliminating the will to remember or input environment IDs.
ENVIRONMENTS=$(echo "$CLEAN_RESPONSE" | jq -r '.site.environments[] | "(.name): (.identity)"')
echo "Available Environments for "$SITE_NAME":"
echo "$ENVIRONMENTS"
be informed -p "Enter the environment name to once more up (e.g., staging, are living): " ENV_NAMEThe selected environment name is then used to seem up its corresponding environment ID from the site details. This ID is wanted for API requests to create a backup.
ENV_ID=$(echo "$CLEAN_RESPONSE" | jq -r --arg ENV_NAME "$ENV_NAME" '.site.environments[] | make a choice(.name == $ENV_NAME) | .identity')
if [ -z "$ENV_ID" ]; then
echo "Error: Environment "$ENV_NAME" not found out for site "$SITE_NAME"."
return 1
fi
echo "Came upon environment ID: $ENV_ID for environment name: $ENV_NAME"Throughout the code above, a scenario is created so that the script exits with an error message if the provided environment name isn’t matched.
Now that you just’ve the environment ID, you’ll have the ability to proceed to check the existing number of information backups for the selected environment. Kinsta’s limit of five information backups consistent with environment way this step is an important to keep away from errors.
Let’s get began by the use of fetching the report of backups using the /backups API endpoint.
API_URL="$BASE_URL/web sites/environments/$ENV_ID/backups"
BACKUPS_RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content material material-Type: software/json")
CLEAN_RESPONSE=$(echo "$BACKUPS_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')
MANUAL_BACKUPS=$(echo "$CLEAN_RESPONSE" | jq '[.environment.backups[] | make a choice(.type == "information")]')
BACKUP_COUNT=$(echo "$MANUAL_BACKUPS" | jq 'period')The script above then filters for information backups and counts them. If the rely reaches the limit, we need to prepare the existing backups:
if [ "$BACKUP_COUNT" -ge 5 ]; then
echo "Information backup limit reached (5 backups)."
# To seek out the oldest backup
OLDEST_BACKUP=$(echo "$MANUAL_BACKUPS" | jq -r 'sort_by(.created_at) | .[0]')
OLDEST_BACKUP_NAME=$(echo "$OLDEST_BACKUP" | jq -r '.apply')
OLDEST_BACKUP_ID=$(echo "$OLDEST_BACKUP" | jq -r '.identity')
echo "The oldest information backup is "$OLDEST_BACKUP_NAME"."
be informed -p "Do you want to delete this backup to create a brand spanking new one? (certain/no): " CONFIRM
if [ "$CONFIRM" != "yes" ]; then
echo "Aborting backup creation."
return 1
fi
# Delete the oldest backup
DELETE_URL="$BASE_URL/web sites/environments/backups/$OLDEST_BACKUP_ID"
DELETE_RESPONSE=$(curl -s -X DELETE "$DELETE_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content material material-Type: software/json")
echo "Delete Response:"
echo "$DELETE_RESPONSE" | jq -r '[
"Operation ID: (.operation_id)",
"Message: (.message)",
"Status: (.status)"
] | join("n")'
fiThe placement above identifies the oldest backup by the use of sorting the report according to the created_at timestamp. It then turns on you to verify whether or not or now not you’d like to delete it.
If you happen to agree, the script deletes the oldest backup using its ID, freeing up space for the new one. This promises that backups can always be created without manually managing limits.
Now that there’s space, let’s proceed with the code to prompt backup for the environment. Feel free to skip this code, alternatively for a better enjoy, it turns on you to specify a custom designed tag, defaulting to “default-backup” if none is supplied.
be informed -p "Enter a backup tag (or press Enter to use "$DEFAULT_TAG"): " BACKUP_TAG
if [ -z "$BACKUP_TAG" ]; then
BACKUP_TAG="$DEFAULT_TAG"
fi
echo "The use of backup tag: $BACKUP_TAG"In spite of everything, the script beneath is where the backup movement happens. It sends a POST request to the /manual-backups endpoint with the selected environment ID and backup tag. If the request is a luck, the API returns a response confirming the backup creation.
API_URL="$BASE_URL/web sites/environments/$ENV_ID/manual-backups"
RESPONSE=$(curl -s -X POST "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content material material-Type: software/json"
-d "{"tag": "$BACKUP_TAG"}")
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API while triggering the information backup."
return 1
fi
echo "Backup Reason Response:"
echo "$RESPONSE" | jq -r '[
"Operation ID: (.operation_id)",
"Message: (.message)",
"Status: (.status)"
] | join("n")'That’s it! The response purchased from the request above is formatted to turn the operation ID, message, and status for clarity. If you happen to call the function and run the script, you’ll see output similar to this:
Available Environments for "example-site":
staging: 12345
are living: 67890
Enter the environment name to once more up (e.g., staging, are living): are living
Came upon environment ID: 67890 for environment name: are living
Information backup limit reached (5 backups).
The oldest information backup is "staging-backup-2023-12-31".
Do you want to delete this backup to create a brand spanking new one? (certain/no): certain
Oldest backup deleted.
Enter a backup tag (or press Enter to use "default-backup"): weekly-live-backup
The use of backup tag: weekly-live-backup
Triggering information backup for environment ID: 67890 with tag: weekly-live-backup...
Backup Reason Response:
Operation ID: backups:add-manual-abc123
Message: Together with a information backup to environment in construction.
Status: 202Rising directions to your script
Directions simplify how your script is used. Instead of improving the script or commenting out code manually, consumers can run it with a decided on command like:
./script.sh list-sites
./script.sh backup At the end of your script (outdoor all of the functions), include a conditional block that checks the arguments passed to the script:
if [ "$1" == "list-sites" ]; then
list_sites
elif [ "$1" == "backup" ]; then
SITE_NAME="$2"
if [ -z "$SITE_NAME" ]; then
echo "Usage: $0 trigger-backup "
move out 1
fi
trigger_manual_backup "$SITE_NAME"
else
echo "Usage: $0 trigger-backup "
move out 1
fiThe $1 variable represents the main argument passed to the script (e.g., in ./script.sh list-sites, $1 is list-sites). The script uses conditional checks to check $1 with specific directions like list-sites or backup. If the command is backup, it moreover expects a second argument ($2), which is the site name. If no reliable command is supplied, the script defaults to displaying usage instructions.
You’ll now prompt a information backup for a decided on site by the use of operating the command:
./script.sh backupDifficult use case 2: Updating plugins all the way through a few web sites
Managing WordPress plugins all the way through a few web sites can be tedious, specifically when updates are available. Kinsta does an excellent procedure coping with this by the use of the MyKinsta dashboard, throughout the majority movement function we introduced ultimate twelve months.
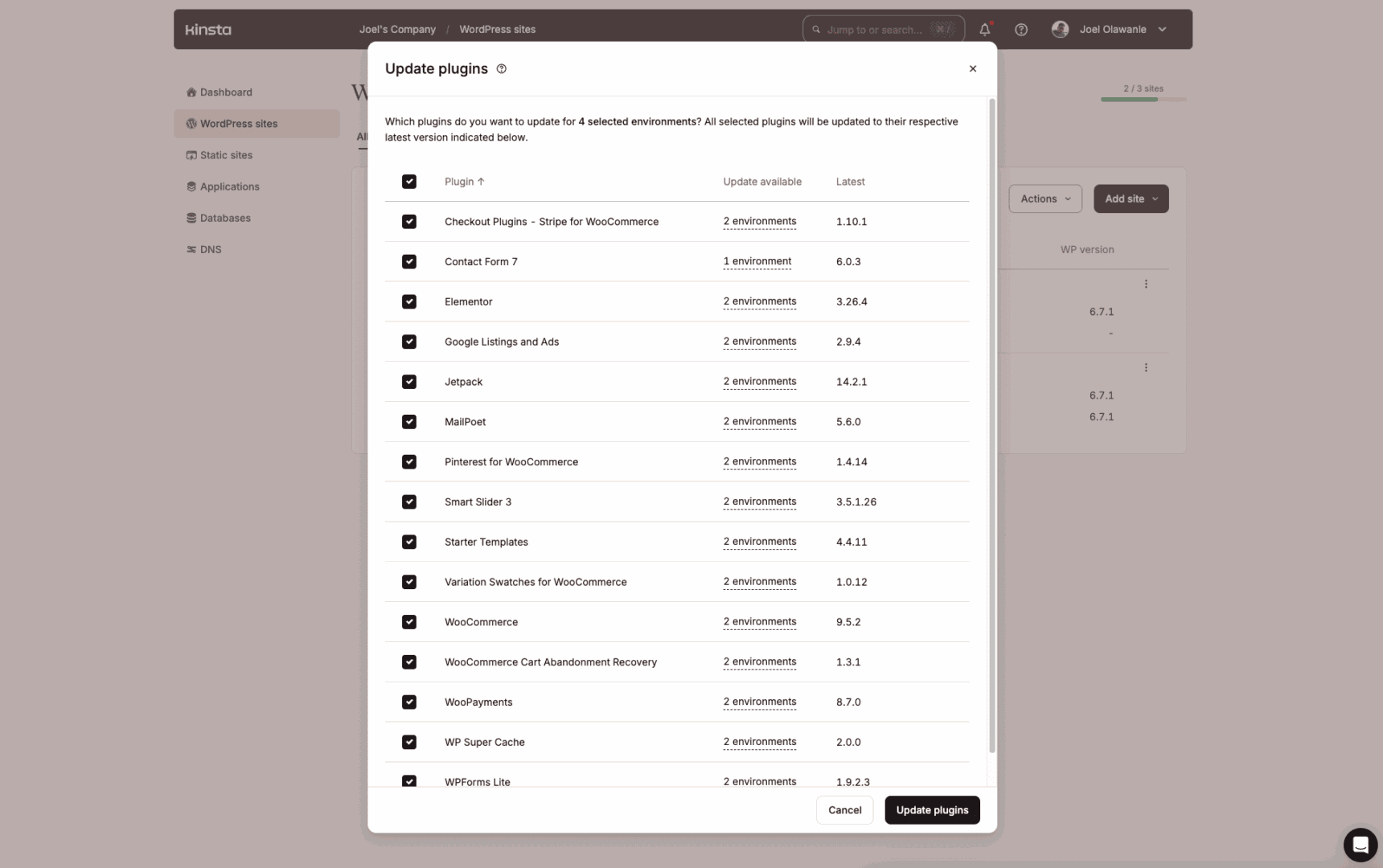
However while you don’t like operating with client interfaces, the Kinsta API provides each different selection to create a shell script to automate the process of working out outdated plugins and updating them all the way through a few web sites or specific environments.
Breaking down the workflow
1. Decide web sites with outdated plugins: The script iterates through all web sites and environments, on the lookout for the specified plugin with an exchange available. The following endpoint is used to fetch the report of plugins for a decided on site environment:
GET /web sites/environments/{env_id}/pluginsFrom the response, we filter for plugins where "exchange": "available".
2. Suggested client for exchange possible choices: It displays the internet sites and environments with the old school plugin, allowing the patron to make a choice specific cases or exchange all of them.
3. Reason plugin updates: To interchange the plugin in a decided on environment, the script uses this endpoint:
PUT /web sites/environments/{env_id}/pluginsThe plugin name and its up-to-the-minute type are passed inside the request body.
The script
Since the script is lengthy, the full function is hosted on GitHub for easy get admission to. Proper right here, we’ll provide an explanation for the core commonplace sense used to identify outdated plugins all the way through a few web sites and environments.
The script starts by the use of accepting the plugin name from the command. This name specifies the plugin you want to switch.
PLUGIN_NAME=$1
if [ -z "$PLUGIN_NAME" ]; then
echo "Error: Plugin name is wanted."
echo "Usage: $0 update-plugin "
return 1
fiThe script then uses the reusable get_sites_list function (outlined earlier) to fetch all web sites inside the company:
echo "Fetching all web sites inside the company..."
# Fetch all web sites inside the company
SITES_RESPONSE=$(get_sites_list)
if [ $? -ne 0 ]; then
echo "Error: Didn't fetch web sites."
return 1
fi
# Clean the response
CLEAN_SITES_RESPONSE=$(echo "$SITES_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Next comes the middle of the script: looping throughout the report of web sites to check for outdated plugins. The CLEAN_SITES_RESPONSE, which is a JSON object containing all web sites, is passed to a few time loop to perform operations for each site one by one.
It starts by the use of extracting some very important data similar to the site ID, name, and display name into variables:
while IFS= be informed -r SITE; do
SITE_ID=$(echo "$SITE" | jq -r '.identity')
SITE_NAME=$(echo "$SITE" | jq -r '.name')
SITE_DISPLAY_NAME=$(echo "$SITE" | jq -r '.display_name')
echo "Checking environments for site "$SITE_DISPLAY_NAME"..."The site name is then used alongside the get_site_details_by_name function defined prior to fetch detailed information about the site, in conjunction with all its environments.
SITE_DETAILS=$(get_site_details_by_name "$SITE_NAME")
CLEAN_SITE_DETAILS=$(echo "$SITE_DETAILS" | tr -d 'r' | sed 's/^[^{]*//')
ENVIRONMENTS=$(echo "$CLEAN_SITE_DETAILS" | jq -r '.site.environments[] | "(.identity):(.name):(.display_name)"')The environments are then looped through to extract details of each environment, such for the reason that ID, name, and display name:
while IFS= be informed -r ENV; do
ENV_ID=$(echo "$ENV" | decrease -d: -f1)
ENV_NAME=$(echo "$ENV" | decrease -d: -f2)
ENV_DISPLAY_NAME=$(echo "$ENV" | decrease -d: -f3)
echo "Checking plugins for environment "$ENV_DISPLAY_NAME"..."For each environment, the script now fetches its report of plugins using the Kinsta API.
PLUGINS_RESPONSE=$(curl -s -X GET "$BASE_URL/web sites/environments/$ENV_ID/plugins"
-H "Authorization: Bearer $API_KEY"
-H "Content material material-Type: software/json")
CLEAN_PLUGINS_RESPONSE=$(echo "$PLUGINS_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Next, the script checks if the specified plugin exists inside the environment and has an available exchange:
OUTDATED_PLUGIN=$(echo "$CLEAN_PLUGINS_RESPONSE" | jq -r --arg PLUGIN_NAME "$PLUGIN_NAME" '.environment.container_info.wp_plugins.data[] | make a choice(.name == $PLUGIN_NAME and .exchange == "available")')If an old school plugin is situated, the script logs its details and gives them to the SITES_WITH_OUTDATED_PLUGIN array:
if [ ! -z "$OUTDATED_PLUGIN" ]; then
CURRENT_VERSION=$(echo "$OUTDATED_PLUGIN" | jq -r '.type')
UPDATE_VERSION=$(echo "$OUTDATED_PLUGIN" | jq -r '.update_version')
echo "Old-fashioned plugin "$PLUGIN_NAME" found in "$SITE_DISPLAY_NAME" (Environment: $ENV_DISPLAY_NAME)"
echo " Provide Style: $CURRENT_VERSION"
echo " Change Style: $UPDATE_VERSION"
SITES_WITH_OUTDATED_PLUGIN+=("$SITE_DISPLAY_NAME:$ENV_DISPLAY_NAME:$ENV_ID:$UPDATE_VERSION")
fiThat’s what the logged details of outdated plugins would seem to be:
Old-fashioned plugin "example-plugin" found in "Internet web page ABC" (Environment: Production)
Provide Style: 1.0.0
Change Style: 1.2.0
Old-fashioned plugin "example-plugin" found in "Internet web page XYZ" (Environment: Staging)
Provide Style: 1.3.0
Change Style: 1.4.0From proper right here, we stock out plugin updates for each plugin using its endpoint. The entire script is in this GitHub repository.
Summary
This newsletter guided you through creating a shell script to engage with the Kinsta API.
Take some time to find the Kinsta API further — you’ll discover additional choices you’ll have the ability to automate to deal with tasks tailored for your specific needs. You must imagine integrating the API with other APIs to enhance decision-making and efficiency.
In spite of everything, steadily examine the MyKinsta dashboard for new choices designed to make internet web page regulate a lot more user-friendly through its intuitive interface.
The post Managing your WordPress websites with shell scripts and Kinsta API appeared first on Kinsta®.

0 Comments