
As any website owner will let you know, wisdom loss and downtime, even in minimal doses, will also be catastrophic. They are able to hit the unprepared at any time, leading to reduced productivity, accessibility, and product self belief.
To give protection to the integrity of your website, it’s essential to build safeguards in opposition to the opportunity of downtime or wisdom loss.
That’s where wisdom replication is to be had in.
As any website online proprietor will inform you that knowledge loss and downtime, even in minimum doses, can also be catastrophic.  Input, knowledge replication
Input, knowledge replication 
Knowledge replication is an automated backup process during which your wisdom is time and again copied from its major database to each and every different, far flung location for safekeeping. It’s an integral technology for any website or app running a database server. You’ll be capable to moreover leverage the replicated database to process read-only SQL, allowing additional processes to be run within the machine.
Putting in replication between two databases offers fault tolerance in opposition to sudden mishaps. It’s considered to be the best method for achieving over the top availability in every single place disasters.
In this article, we’ll dive into the opposite strategies that can be performed by way of backend builders for seamless PostgreSQL replication.
What Is PostgreSQL Replication?
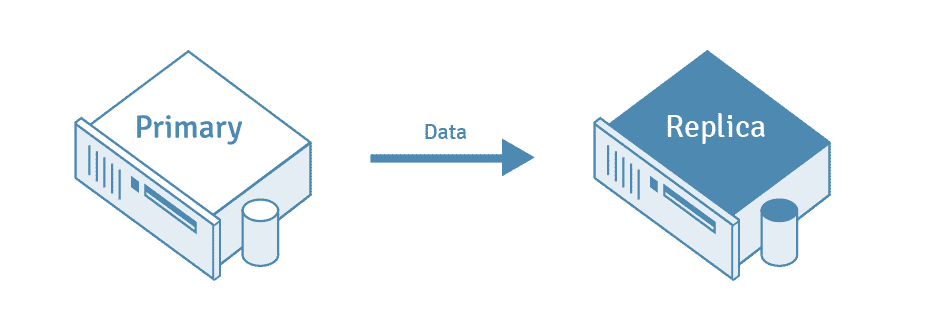
PostgreSQL replication is printed as the process of copying wisdom from a PostgreSQL database server to each and every different server. The availability database server is continuously known as the “primary” server, whilst the database server receiving the copied wisdom is known as the “replica” server.
The PostgreSQL database follows a very easy replication type, where all writes go to a primary node. The principle node can then observe the ones changes and broadcast them to secondary nodes.
What Is Computerized Failover?
Once physically streaming replication has been configured in PostgreSQL, failover can occur if the database’s primary server fails. Failover is used to stipulate the recovery process, which is in a position to take a little time, as it doesn’t provide built-in apparatus to scope out server disasters.
You don’t wish to be relying on PostgreSQL for failover. There are faithful apparatus that allow automatic failover and automatic switching to the standby, slicing down on database downtime.
Via setting up failover replication, you all on the other hand be sure that over the top availability by way of ensuring that standbys are available if the primary server ever collapses.
Benefits of Using PostgreSQL Replication
Listed here are a few key benefits of leveraging PostgreSQL replication:
- Knowledge migration: You’ll be capable to leverage PostgreSQL replication for wisdom migration each via a transformation of database server {{hardware}} or via machine deployment.
- Fault tolerance: If the primary server fails, the standby server can act as a server given that contained wisdom for each and every primary and standby servers is similar.
- Online transactional processing (OLTP) potency: You’ll be capable to toughen the transaction processing time and query time of an OLTP machine by way of eliminating reporting query load. Transaction processing time is the duration it takes for a given query to be performed forward of a transaction is finished.
- Software testing in parallel: While upgrading a brand spanking new machine, you wish to have to ensure that the machine fares neatly with provide wisdom, due to this fact the want to try with a producing database copy forward of deployment.
How PostgreSQL Replication Works
Usually, people believe whilst you’re dabbling with a primary and secondary construction, there’s only one way to arrange backups and replication, on the other hand PostgreSQL deployments practice one of the following 3 approaches:
- Amount level replication to duplicate at the storage layer from the primary to the secondary node, followed by way of backing it up to blob/S3 storage.
- PostgreSQL streaming replication to duplicate wisdom from the primary to the secondary node, followed by way of backing it up to blob/S3 storage.
- Taking incremental backups from the primary node to S3 while reconstructing a brand spanking new secondary node from S3. When the secondary node is throughout the group of the primary, you’ll be capable to get began streaming from the primary node.
Way 1: Streaming
PostgreSQL streaming replication continuously known as WAL replication will also be organize seamlessly after setting up PostgreSQL on all servers. This strategy to replication is in step with moving the WAL information from the primary to the target database.
You’ll be capable to enforce PostgreSQL streaming replication by way of the usage of a primary-secondary configuration. The principle server is the main instance that handles the primary database and all its operations. The secondary server acts since the supplementary instance and executes all changes made to the primary database on itself, generating an equivalent copy throughout the process. The principle is the be told/write server whilst the secondary server is just read-only.
For this technique, you wish to have to configure each and every the primary node and the standby node. The following sections will elucidate the steps fascinated with configuring them very simply.
Configuring Primary Node
You’ll be capable to configure the primary node for streaming replication by way of dressed in out the following steps:
Step 1: Initialize the Database
To initialize the database, you’ll be capable to leverage the initidb software command. Next, you’ll be capable to create a brand spanking new shopper with replication privileges thru the usage of the following command:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';The patron will have to provide a password and username for the given query. The replication keyword is used to provide the shopper the desired privileges. An example query would look something like this:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'Step 2: Configure Streaming Houses
Next, you’ll be capable to configure the streaming homes with the PostgreSQL configuration file (postgresql.conf) that can be modified as follows:
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onProper right here’s slightly of background around the parameters used throughout the previous snippet:
wal_log_hints: This parameter is wanted for thepg_rewindcapability that turns out to be useful when the standby server’s out of sync with the primary server.wal_level: You’ll be capable to use this parameter to allow PostgreSQL streaming replication, with conceivable values along sideminimal,replica, orlogical.max_wal_size: This can be used to specify the size of WAL information that can be retained in log information.hot_standby: You’ll be capable to leverage this parameter for a read-on connection with the secondary when it’s set to ON.max_wal_senders: You’ll be capable to usemax_wal_sendersto specify the maximum number of concurrent connections that can be established with the standby servers.
Step 3: Create New Get admission to
After you’ve modified the parameters throughout the postgresql.conf file, a brand spanking new replication get right of entry to throughout the pg_hba.conf file can allow the servers to resolve a connection with each and every other for replication.
You’ll be capable to typically to search out this file throughout the wisdom record of PostgreSQL. You’ll be capable to use the following code snippet for the same:
host replication rep_user IPaddress md5As quickly because the code snippet gets performed, the primary server we could in a client known as rep_user to attach and act since the standby server by way of the usage of the desired IP for replication. For instance:
host replication rep_user 192.168.0.22/32 md5Configuring Standby Node
To configure the standby node for streaming replication, practice the ones steps:
Step 1: Once more Up Primary Node
To configure the standby node, leverage the pg_basebackup software to generate a backup of the primary node. This may occasionally increasingly more serve as a place to begin for the standby node. You’ll be capable to use this software with the following syntax:
pg_basebackp -D -h -X flow -c fast -U rep_user -WThe parameters used throughout the syntax mentioned above are as follows:
-h: You’ll be capable to use this to mention the primary host.-D: This parameter indicates the record you’re in recent years running on.-C: You’ll be capable to use this to set the checkpoints.-X: This parameter can be used to include the essential transactional log information.-W: You’ll be capable to use this parameter to urged the shopper for a password forward of linking to the database.
Step 2: Set Up Replication Configuration Record
Next, you wish to have to check if the replication configuration file exists. If it doesn’t, you’ll be capable to generate the replication configuration file as recovery.conf.
You will have to create this file throughout the wisdom record of the PostgreSQL arrange. You’ll be capable to generate it mechanically by way of the usage of the -R risk within the pg_basebackup software.
The recovery.conf file will have to include the following directions:
standby_mode = ‘on’
primary_conninfo = ‘host= port= shopper= password= application_name=”host_name”‘
recovery_target_timeline = ‘latest’
The parameters used throughout the aforementioned directions are as follows:
primary_conninfo: You’ll be capable to use this to make a connection between the primary and secondary servers by way of leveraging a connection string.standby_mode: This parameter would possibly reason the primary server to start since the standby when switched ON.recovery_target_timeline: You’ll be capable to use this to set the recovery time.
To organize a connection, you wish to have to provide the username, IP deal with, and password as values for the primary_conninfo parameter. For instance:
primary_conninfo = 'host=192.168.0.26 port=5432 shopper=rep_user password=rep_pass'Step 3: Restart Secondary Server
After all, you’ll be capable to restart the secondary server to complete the configuration process.
Alternatively, streaming replication comes with quite a lot of challenging eventualities, an identical to:
- Various PostgreSQL shoppers (written in numerous programming languages) keep up a correspondence with a single endpoint. When the primary node fails, the ones shoppers will keep retrying the equivalent DNS or IP determine. This makes failover visible to the appliance.
- PostgreSQL replication doesn’t come with built-in failover and monitoring. When the primary node fails, you wish to have to market it a secondary to be the new primary. This promotion will have to be performed by hook or by crook where shoppers write to only one primary node, they usually don’t observe wisdom inconsistencies.
- PostgreSQL replicates its entire state. When you wish to have to develop a brand spanking new secondary node, the secondary will have to recap all the history of state trade from the primary node, which is resource-intensive and makes it dear to eliminate nodes throughout the head and create new ones.
Way 2: Replicated Block Instrument
The replicated block device components depends upon disk mirroring (continuously known as amount replication). In this components, changes are written to a protracted amount which can get synchronously mirrored to each and every different amount.
The additional advantage of this technique is its compatibility and data durability in cloud environments with all relational databases, along side PostgreSQL, MySQL, and SQL Server, to name a few.
Alternatively, the disk-mirroring strategy to PostgreSQL replication needs you to duplicate each and every WAL log and table wisdom. Since each and every write to the database now needs to transport over the group synchronously, you’ll be capable to’t manage to pay for to lose a single byte, as that would leave your database in a corrupt state.
This system is usually leveraged the usage of Azure PostgreSQL and Amazon RDS.
Way 3: WAL
WAL consists of segment information (16 MB by way of default). Each segment has quite a lot of information. A log collection file (LSN) is a pointer to a file in WAL, letting the site/location where the file has been saved throughout the log file.
A standby server leverages WAL segments — continuously known as XLOGS in PostgreSQL terminology — to regularly replicate changes from its primary server. You’ll be capable to use write-ahead logging to grant durability and atomicity in a DBMS by way of serializing chunks of byte-array wisdom (each and every one with a novel LSN) to robust storage forward of they get applied to a database.
Applying a mutation to a database would perhaps lead to relatively a large number of file machine operations. A pertinent question that comes up is how a database can ensure atomicity throughout the match of a server failure on account of a power outage while it was once in the course of a file machine updation. When a database boots, it begins a startup or replay process which is in a position to be told the available WAL segments and compares them with the LSN stored on each and every wisdom internet web page (each and every wisdom internet web page is marked with the LSN of the newest WAL file that has effects on the internet web page).
Log Delivery-Based totally completely Replication (Block Level)
Streaming replication refines the log supply process. As opposed to taking a look ahead to the WAL switch, the knowledge are sent as they get created, thus lowering replication extend.
Streaming replication moreover trumps log supply given that standby server links with the primary server over the group by way of leveraging a replication protocol. The principle server can then send WAL information instantly over this connection with out a wish to depend on scripts equipped by way of the end-user.
Log Delivery-Based totally completely Replication (Record Level)
Log supply is printed as copying log information to each and every different PostgreSQL server to generate each and every different standby server by way of replaying WAL information. This server is configured to art work in recovery mode, and its sole purpose is to make use of any new WAL information as they show up.
This secondary server then turns right into a warmth backup of the primary PostgreSQL server. It will also be configured to be a be told replica, where it is going to perhaps offer read-only queries, moreover referred to as sizzling standby.
Secure WAL Archiving
Duplicating WAL information as they’re created into any location fairly then the pg_wal subdirectory to archive them is known as WAL archiving. PostgreSQL will title a script given by way of the shopper for archiving, each and every time a WAL file gets created.
The script can leverage the scp command to copy the file to quite a lot of puts an identical to an NFS mount. Once archived, the WAL segment information will also be leveraged to recuperate the database at any given point in time.
Other log-based configurations include:
- Synchronous replication: Previous to each and every synchronous replication transaction gets devoted, the primary server waits until standbys confirm that they got the data. The benefit of this configuration is that there won’t be any conflicts led to on account of parallel writing processes.
- Synchronous multi-master replication: Proper right here, each and every server can accept write requests, and adjusted wisdom gets transmitted from the original server to each and every other server forward of each and every transaction gets devoted. It leverages the 2PC protocol and adheres to the all-or-none rule.
WAL Streaming Protocol Details
A process known as WAL receiver, running on the standby server, leverages the connection details equipped throughout the primary_conninfo parameter of recovery.conf and connects to the primary server by way of leveraging a TCP/IP connection.
To start streaming replication, the frontend can send the replication parameter within the startup message. A Boolean value of true, certain, 1, or ON lets the backend know that it needs to go into physically replication walsender mode.
WAL sender is each and every different process that runs on the primary server and is answerable for sending the WAL information to the standby server as they get generated. The WAL receiver saves the WAL information in WAL as although they’ve been created by way of consumer activity of in the community connected shoppers.
As quickly because the WAL information be triumphant within the WAL segment information, the standby server often keeps replaying the WAL so that primary and standby are up to date.

Parts of PostgreSQL Replication
In this segment, you’ll reach a deeper figuring out of the typically used models (single-master and multi-master replication), types (physically and logical replication), and modes (synchronous and asynchronous) of PostgreSQL replication.
Models of PostgreSQL Database Replication
Scalability method together with additional property/ {{hardware}} to provide nodes to enhance the power of the database to store and process additional wisdom which will also be finished horizontally and vertically. PostgreSQL replication is an example of horizontal scalability which is much more tough to enforce than vertical scalability. We will be able to succeed in horizontal scalability principally by way of single-master replication (SMR) and multi-master replication (MMR).
Single-master replication we could in wisdom to be modified only on a single node, and the ones changes are replicated to quite a lot of nodes. The replicated tables throughout the replica database aren’t licensed to easily settle for any changes, except those from the primary server. Even though they do, the changes aren’t replicated once more to the primary server.
More often than not, SMR is enough for the appliance because it’s more effective to configure and arrange along side no chances of conflicts. Single-master replication may be unidirectional, since replication wisdom flows in one trail principally, from the primary to the replica database.
In some cases, SMR on my own might not be sufficient, and also you’ll want to enforce MMR. MMR we could in more than one node to act as the primary node. Changes to table rows in more than one designated primary database are replicated to their counterpart tables in each and every other primary database. In this type, combat resolution schemes are often employed to steer clear of problems like replica primary keys.
There are a few advantages to the usage of MMR, in particular:
- In relation to host failure, other hosts can however give substitute and insertion services.
- The principle nodes are spread out in several different puts, so the chance of failure of all primary nodes may well be very small.
- Talent to make use of a giant area group (WAN) of primary databases that can be geographically when it comes to groups of shoppers, however handle wisdom consistency across the group.
Alternatively, the downside of imposing MMR is the complexity and its factor to unravel conflicts.
Quite a lot of branches and programs provide MMR solutions as PostgreSQL doesn’t give a boost to it natively. The ones solutions could also be open-source, free, or paid. One such extension is bidirectional replication (BDR) which is asynchronous and is in step with the PostgreSQL logical interpreting function.
Given that BDR tool replays transactions on other nodes, the replay operation may fail if there’s a combat between the transaction being applied and the transaction devoted on the receiving node.
Types of PostgreSQL Replication
There are two types of PostgreSQL replication: logical and physically replication.
A simple logical operation “initdb” would carry out the physically operation of creating a base record for a cluster. Likewise, a simple logical operation “CREATE DATABASE” would carry out the physically operation of creating a subdirectory throughout the base record.
Physically replication typically gives with information and directories. It doesn’t know what the ones information and directories represent. The ones methods are used to handle a whole copy of all the wisdom of a single cluster, typically on each and every different software, and are finished at the file machine level or disk level and use exact block addresses.
Logical replication is a way of reproducing wisdom entities and their changes, based upon their replication identification (typically a primary key). No longer like physically replication, it gives with databases, tables, and DML operations and is done at the database cluster level. It uses a publish and subscribe type where quite a lot of subscribers are subscribed to quite a lot of publications on a creator node.
The replication process starts by way of taking a snapshot of the data on the creator database and then copying it to the subscriber. Subscribers pull wisdom from the publications they subscribe to and may re-publish wisdom later to allow cascading replication or additional sophisticated configurations. The subscriber applies the data within the equivalent order since the creator so that transactional consistency is confident for publications inside a single subscription continuously known as transactional replication.
The usual use cases for logical replication are:
- Sending incremental changes in a single database (or a subset of a database) to subscribers as they occur.
- Sharing a subset of the database between multiple databases.
- Triggering the firing of specific individual changes as they arrive on the subscriber.
- Consolidating multiple databases into one.
- Providing get right of entry to to replicated wisdom to different groups of consumers.
The subscriber database behaves within the equivalent approach as each and every different PostgreSQL instance and can be used as a creator for various databases by way of defining its publications.
When the subscriber is treated as read-only by way of tool, there’ll be no conflicts from a single subscription. Then again, if there are other writes finished each by way of an tool or by way of other subscribers to the equivalent set of tables, conflicts can stand up.
PostgreSQL is helping each and every mechanisms concurrently. Logical replication we could in fine-grained control over each and every wisdom replication and protection.
Replication Modes
There are principally two modes of PostgreSQL replication: synchronous and asynchronous. Synchronous replication we could in wisdom to be written to each and every the primary and secondary server at the equivalent time, whilst asynchronous replication promises that the data is first written to the host and then copied to the secondary server.
In synchronous mode replication, transactions on the primary database are considered entire only when those changes were replicated to all the replicas. The replica servers will have to all be available always for the transactions to be completed on the primary. The synchronous mode of replication is used in high-end transactional environments with speedy failover must haves.
In asynchronous mode, transactions on the primary server will also be declared entire when the changes were finished on merely the primary server. The ones changes are then replicated throughout the replicas later in time. The replica servers can keep out-of-sync for a definite duration, known as a replication lag. In relation to a crash, wisdom loss may occur, on the other hand the overhead equipped by way of asynchronous replication is small, so it’s suitable usually (it doesn’t overburden the host). Failover from the primary database to the secondary database takes longer than synchronous replication.
How To Set Up PostgreSQL Replication
For this segment, we’ll be demonstrating find out how to organize the PostgreSQL replication process on a Linux operating machine. For this case, we’ll be the usage of Ubuntu 18.04 LTS and PostgreSQL 10.
Let’s dig in!
Arrange
You’ll get started by way of setting up PostgreSQL on Linux with the ones steps:
- Initially, you’d will have to import the PostgreSQL signing key by way of typing the underneath command throughout the terminal:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Then, add the PostgreSQL repository by way of typing the underneath command throughout the terminal:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg major" | sudo tee /and so forth/apt/assets.tick list.d/postgresql.tick list - Substitute the Repository Index by way of typing the following command throughout the terminal:
sudo apt-get substitute - Arrange PostgreSQL bundle deal the usage of the apt command:
sudo apt-get arrange -y postgresql-10 - After all, set the password for the PostgreSQL shopper the usage of the following command:
sudo passwd postgres
The arrange of PostgreSQL is mandatory for each and every the primary and the secondary server forward of starting the PostgreSQL replication process.
If you happen to’ve organize PostgreSQL for each and every the servers, you should switch immediately to the replication set-up of the primary and the secondary server.
Surroundings Up Replication in Primary Server
Carry out the ones steps while you’ve installed PostgreSQL on each and every primary and secondary servers.
- Initially, log in to the PostgreSQL database with the following command:
su - postgres - Create a replication shopper with the following command:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Edit pg_hba.cnf with any nano tool in Ubuntu and add the following configuration: file edit command
nano /and so forth/postgresql/10/major/pg_hba.confTo configure the file, use the following command:
host replication replication MasterIP/24 md5 - Open and edit postgresql.conf and put the following configuration in the primary server:
nano /and so forth/postgresql/10/major/postgresql.confUse the following configuration settings:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - After all, restart PostgreSQL in primary major server:
systemctl restart postgresqlYou’ve now completed the setup in the primary server.
Surroundings Up Replication in Secondary Server
Practice the ones steps to prepare replication throughout the secondary server:
- Login to PostgreSQL RDMS with the command underneath:
su - postgres - Save you the PostgreSQL supplier from running to allow us to art work on it with the command underneath:
systemctl save you postgresql - Edit pg_hba.conf file with this command and add the following configuration:
Edit Command
nano /and so forth/postgresql/10/major/pg_hba.confConfiguration
host replication replication MasterIP/24 md5 - Open and edit postgresql.conf throughout the secondary server and put the following configuration or uncomment if it’s commented:Edit Command
Configuration
nano /and so forth/postgresql/10/major/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP is the deal with of the secondary server
- Get admission to the PostgreSQL wisdom record throughout the secondary server and remove the whole thing:
cd /var/lib/postgresql/10/majorrm -rfv * - Copy PostgreSQL primary server wisdom record information to PostgreSQL secondary server wisdom record and write this command throughout the secondary server:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/major/ -P -Ureplication --wal-method=fetch - Enter the primary server PostgreSQL password and press enter. Next, add the following command for the recovery configuration: Edit Command
nano /var/lib/postgresql/10/major/recovery.confConfiguration
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 shopper=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Proper right here, YOUR_PASSWORD is the password for the replication shopper in the primary server PostgreSQL created
- As quickly because the password has been set, you’d will have to restart the secondary PostgreSQL database as it was once stopped:
systemctl get began postgresqlTesting Your Setup
Now that we’ve carried out the steps, let’s check out the replication process and observe the secondary server database. For this, we create a table in the primary server and observe if the equivalent is reflected on the secondary server.
Let’s get to it.
- Since we’re growing the table in the primary server, you’d want to login to the primary server:
su - postgres psql - Now we create a simple table named ‘testtable’ and insert wisdom to the table by way of running the following PostgreSQL queries throughout the terminal:
CREATE TABLE testtable (internet websites varchar(100)); INSERT INTO testtable VALUES ('segment.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Practice the secondary server PostgreSQL database by way of logging in to the secondary server:
su - postgres psql - Now, we check if the table ‘testtable’ exists, and can return the data by way of running the following PostgreSQL queries throughout the terminal. This command essentially displays all the table.
select * from testtable;
That’s the output of the check out table:
| internet websites |
-------------------
| segment.com |
| google.com |
| github.com |
--------------------You will have to be capable to observe the equivalent wisdom as the one in the primary server.
Must you notice the above, then you’ve got successfully carried out the replication process!
What Are the PostgreSQL Guide Failover Steps?
Let’s go over the steps for a PostgreSQL information failover:
- Crash the primary server.
- Put it on the market the standby server by way of running the following command on the standby server:
./pg_ctl market it -D ../sb_data/ server promoting - Connect to the promoted standby server and insert a row:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Sort "be in agreement" for be in agreement. edb=# insert into abc values(4,'4');
If the insert works great, then the standby, previously a read-only server, has been promoted as the new primary server.
How To Automate Failover in PostgreSQL
Putting in automatic failover is modest.
You’ll need the EDB PostgreSQL failover manager (EFM). After downloading and setting up EFM on each and every primary and standby node, you’ll be capable to create an EFM Cluster, which consists of a primary node, quite a lot of Standby nodes, and an optional Witness node that confirms assertions in case of failure.
EFM regularly displays machine neatly being and sends electronic message signs in step with machine events. When a failure occurs, it mechanically switches over to one of the most up-to-date standby and reconfigures all other standby servers to recognize the new primary node.
It moreover reconfigures load balancers (an identical to pgPool) and stops “split-brain” (when two nodes each and every think they’re primary) from occurring.
Summary
As a result of over the top amounts of knowledge, scalability and protection have become two of the most important requirements in database control, in particular in a transaction environment. While we can toughen scalability vertically by way of together with additional property/{{hardware}} to provide nodes, it isn’t always conceivable, often on account of the associated fee or hindrances of together with new {{hardware}}.
Due to this fact, horizontal scalability is wanted, which means that that together with additional nodes to provide group nodes rather than making improvements to the aptitude of provide nodes. That’s the position PostgreSQL replication comes into the picture.
To offer protection to the integrity of your website online, it’s necessary to construct safeguards towards the potential of downtime or knowledge loss.  Be told extra on this information
Be told extra on this information 
In this article, we’ve discussed the types of PostgreSQL replications, benefits, replication modes, arrange, and PostgreSQL failover Between SMR and MMR. Now let’s concentrate from you.
Which one do you typically enforce? Which database function is the most important to you and why? We’d like to be told your concepts! Percentage them throughout the comments segment underneath.
The put up PostgreSQL Replication: A Complete Information appeared first on Kinsta®.
Contents
- 1 What Is PostgreSQL Replication?
- 2 Benefits of Using PostgreSQL Replication
- 3 How PostgreSQL Replication Works
- 4 Parts of PostgreSQL Replication
- 5 How To Set Up PostgreSQL Replication
- 6 What Are the PostgreSQL Guide Failover Steps?
- 7 How To Automate Failover in PostgreSQL
- 8 Summary
- 9 The right way to Use Invisible Dividers to Create House Between Divi Modules
- 10 Pronouncing WPBeginner Professional Services and products: Customized WordPress Web site Design, Rep...
- 11 Instagram Reels for Designers – How I Grew 4x in One Month

0 Comments