
Large Language Models (LLMs) have changed how we assemble and use device. While cloud-based LLM APIs are great for convenience, there are lots of reasons to run them locally, at the side of upper privacy, lower costs for experimentation, the power to art work offline, and faster trying out without able on group delays.
On the other hand running Large Language Models (LLMs) on your own device most often is a headache as it without end involves dealing with refined setups, hardware-specific issues, and serve as tuning.
That’s the position Docker Fashion Runner is to be had in. At the time of this writing, it’s in recent years in Beta, it’s designed to simplify the entire thing via packaging LLMs in easy-to-run Docker packing containers.
Let’s see how it works.
Must haves
Must haves vary depending on your operating device. Beneath are the minimum must haves for running Docker Style Runner.
| Running System | Must haves |
|---|---|
| macOS |
|
| House home windows |
|
Enabling Docker Style Runner
After getting met the prerequisites, you’ll have the ability to proceed with the arrange and setup of Docker Style Runner with the following command.
docker desktop permit model-runner
If you want to allow other apps to connect the Style Runner’s endpoint, you’ll want to permit TCP host get admission to on a port. For example, to use port 5000:
docker desktop permit model-runner --tcp 5000
This will likely once in a while expose the Style Runner’s endpoint on localhost:5000. You’ll have the ability to trade the port amount to a couple different port you prefer or available to your host device. The API is also OpenAI-compatible, so that you’ll have the ability to use it with any OpenAI-compatible consumer.
Running a Style
Models are pulled from Docker Hub the main time you utilize them and will be stored locally, similar to a Docker image.
Let’s say we wish to run Gemma3, a moderately tricky LLM from Google that we can use for various tasks like text generation, summarization, and additional. To run it, we first pull the following command:
docker model pull ai/gemma3
Similar to pulling a Docker image, if the mannequin isn’t specified, it’ll pull the latest mannequin or variant. In our case, this is in a position to pull the model with 4B parameters and 131K context period. You’ll have the ability to keep watch over the command to pull a definite mannequin or variant if sought after, harking back to ai/gemma3:1B-Q4_K_M for the 1B mannequin with quantization.
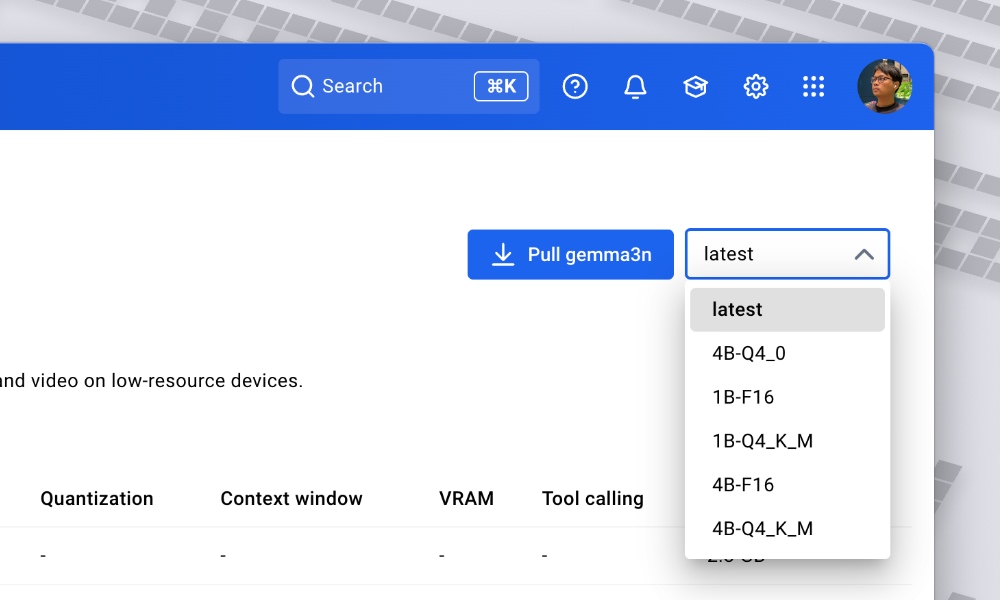
Alternatively, you’ll have the ability to click on at the “Pull” from the Docker Desktop, and select which mannequin you’d like to pull:
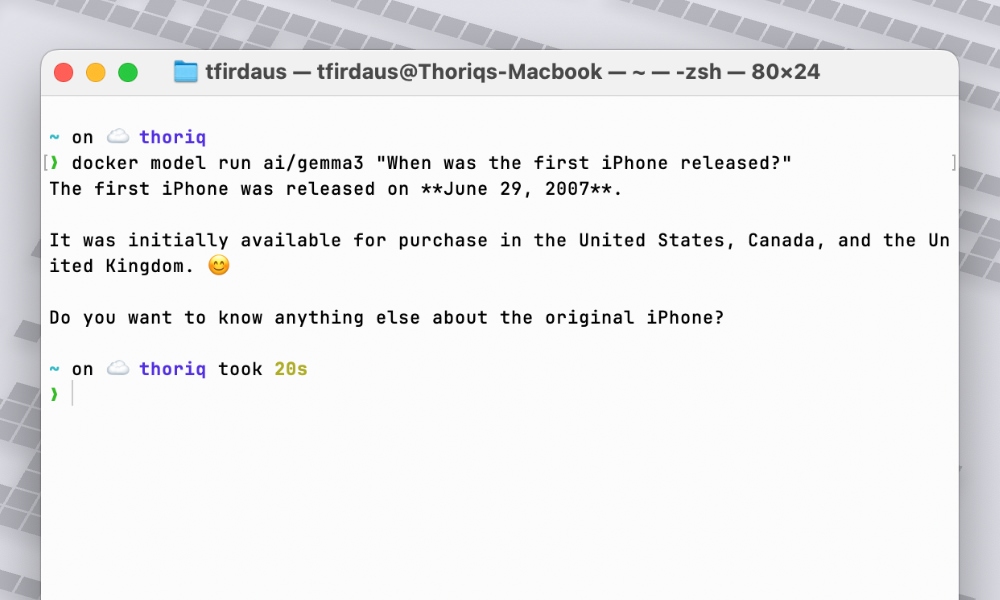
To run the model, we can use the docker model run command. For example, in this case, I’d ask it a question regarding the first iPhone release date:
docker model run ai/gemma3 "When used to be as soon as the main iPhone introduced?"
Certain enough it returns the right kind answer:
Running with Docker Compose
What’s interesting right here’s that you just’ll have the ability to moreover use and run the models with Docker Compose. So as a substitute of merely running a model by itself, you’ll have the ability to define the model alongside your other products and services and merchandise to your compose.yaml document.
For example, think that we wish to run a WordPress website online, and we moreover wish to use the Gemma3 model for text generation to allow us to generate draft blog posts and articles in short within our WordPress. We can prepare our compose.yaml, like this:
products and services and merchandise:
app:
image: wordpress:latest
models:
- gemma
- embedding-model
models:
llm:
model: ai/gemma3
As mentioned, the Style’s endpoint is offered every internally during the hooked up products and services and merchandise throughout the Docker group and externally from your host device, as confirmed below.
| Get right to use | Endpoint |
|---|---|
| From Container | http://model-runner.docker.within/engines/v1 |
| From Host device | http://localhost:5000/engines/v1, assuming you put the tcp port to 5000 |
Given that endpoint is OpenAI-compatible, you’ll have the ability to use it with any OpenAI-compatible consumer such because the authentic SDK libraries. For example, below is how shall we use it with the OpenAI JavaScript SDK.
import OpenAI from "openai";
const consumer = new OpenAI({
apiKey: "",
baseURL: "http://localhost:5000/engines/v1",
});
const response = look ahead to consumer.responses.create({
model: "ai/gemma3",
input: "When used to be as soon as the main iPhone introduced?"
});
console.log(response.output_text);
And that’s it! You’ll have the ability to now run LLMs in Docker comfortably, and use them to your techniques.
Wrapping up
Docker Style Runner is an outstanding device that simplifies the process of running Large Language Models locally. It abstracts away the complexities of setup and configuration, specifically when you’re working with a few models, products and services and merchandise and team. In order that you and your team can point of interest on building techniques without worrying so much on the underlying setup or configuration.
The submit Run LLM in Docker appeared first on Hongkiat.
Supply: https://www.hongkiat.com/blog/docker-llm-setup-guide/
Contents
- 1 Must haves
- 2 Enabling Docker Style Runner
- 3 Running a Style
- 4 Running with Docker Compose
- 5 Wrapping up
- 6 WP Engine Vs. Mullenweg: WordPress Safety Showdown: WP Engine Vs….
- 7 Why You Should not Purchase Instagram Fans (& What Mavens Say to Do As an alternative)
- 8 4 Creative Carousel Transitions You Can Apply In Divi 5

0 Comments