
For lots of marketers, constant updates are needed to keep their internet web page recent and toughen their search engine optimization rankings.
On the other hand, some web pages have quite a bit or even 1000’s of pages, making it an issue for teams that manually push the updates to serps. If the content material subject matter is being up to the moment so ceaselessly, how can teams ensure that the ones improvements are impacting their search engine marketing scores?
That’s where crawler bots come into play. A web crawler bot will scrape your sitemap for brand new updates and index the content material subject matter into serps.
In this put up, we’ll outline an entire crawler tick list that covers all the web crawler bots you want to grasp. Faster than we dive in, let’s define web crawler bots and show how they function.
What Is a Web Crawler?
A web crawler is a computer program that mechanically scans and systematically reads web pages to index the pages for serps. Web crawlers are often referred to as spiders or bots.
For serps to supply up-to-date, similar web pages to consumers beginning up a search, a transfer slowly from a web crawler bot will have to occur. This process can infrequently happen mechanically (depending on every the crawler’s and your internet web page’s settings), or it can be initiated directly.
Many parts affect your pages’ search engine marketing rating, along side relevancy, backlinks, internet internet hosting, and further. On the other hand, none of the ones matter if your pages aren’t being crawled and indexed by the use of serps. Because of this it’s so crucial to ensure that your internet web page is allowing the correct crawls to occur and eliminating any limitations in their way.
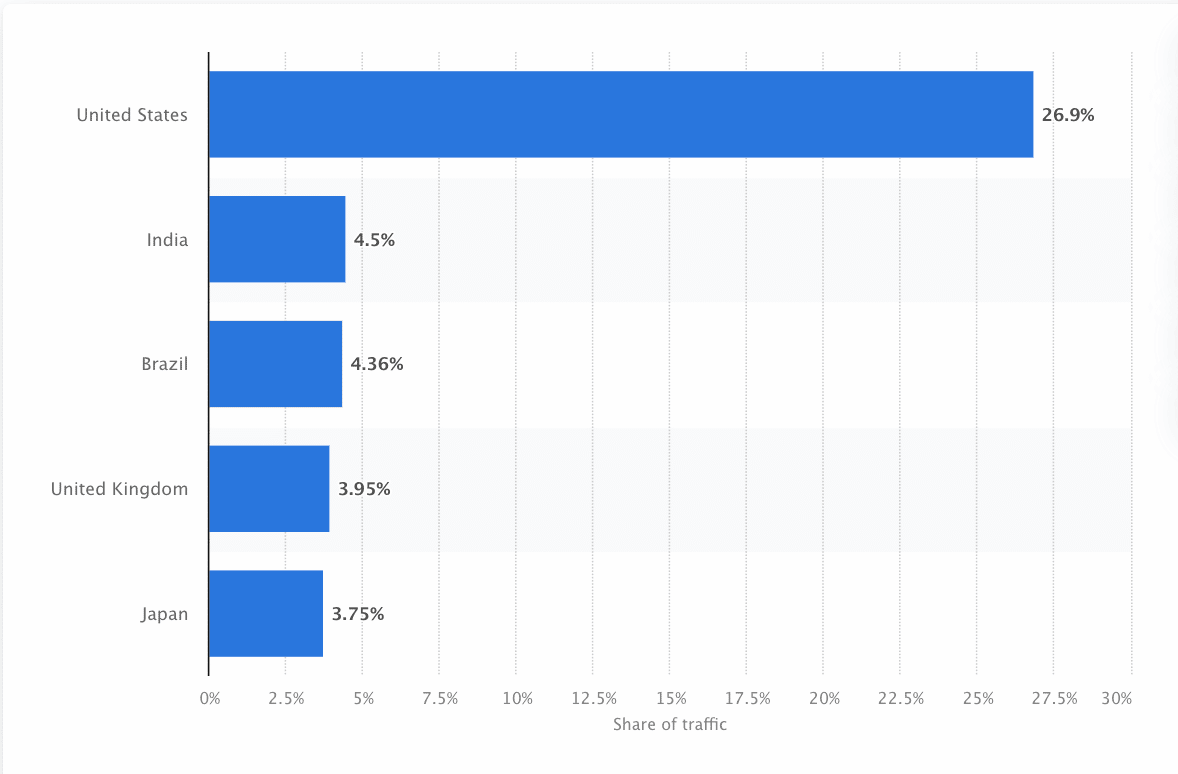
Bots will have to ceaselessly scan and scrape the internet to make sure one of the vital right kind wisdom is presented. Google is probably the most visited site in the US, and kind of 26.9% of searches come from American consumers:
On the other hand, there isn’t one web crawler that crawls for every search engine. Every seek engine has unique strengths, so developers and marketers infrequently gather a “crawler tick list.” This crawler tick list helps them resolve different crawlers in their internet web page log to easily settle for or block.
Marketers want to gather a crawler tick list full of the opposite web crawlers and understand how they evaluation their internet web page (no longer like content material scrapers that scouse borrow the content material subject matter) to ensure that they optimize their landing pages correctly for serps.
How Does a Web Crawler Artwork?
A web crawler will mechanically scan your web internet web page after it’s revealed and index your information.
Web crawlers seek for specific keywords associated with the web internet web page and index that wisdom for similar serps like Google, Bing, and further.
Algorithms for the various search engines will fetch that knowledge when an individual submits an inquiry for the similar keyword that is tied to it.
Crawls get began with recognized URLs. The ones are established web pages with quite a lot of signs that direct web crawlers to those pages. The ones signs might be:
- Inbound links: The number of events a internet web page links to it
- Visitors: How so much visitors is heading to that internet web page
- House Authority: All the top quality of the realm
Then, they store the guidelines throughout the search engine’s index. Since the particular person initiates a search query, the algorithm will fetch the guidelines from the index, and it’s going to appear on the search engine results internet web page. This process can occur inside a few milliseconds, which is why results ceaselessly appear quickly.
As a webmaster, you’ll be capable of regulate which bots transfer slowly your internet web page. That’s why it’s crucial to have a crawler tick list. It’s the robots.txt protocol that lives inside each internet web page’s servers that directs crawlers to new content material subject matter that will have to be indexed.
Depending on what you input into your robots.txt protocol on each web internet web page, you’ll be capable of tell a crawler to scan or steer clear of indexing that internet web page someday.
By the use of understanding what a web crawler appears to be for in its scan, you’ll be capable of understand how to raised position your content material subject matter for serps.
Compiling Your Crawler List: What Are the Different Kinds of Web Crawlers?
As you start to think about compiling your crawler tick list, there are 3 number one forms of crawlers to seek for. The ones include:
- In-house Crawlers: The ones are crawlers designed by the use of a company’s construction team of workers to scan its internet web page. In most cases they’re used for internet web page auditing and optimization.
- Commercial Crawlers: The ones are custom-built crawlers like Screaming Frog that companies can use to transport slowly and effectively evaluation their content material subject matter.
- Open-Provide Crawlers: The ones are free-to-use crawlers which can also be built by the use of numerous developers and hackers all over the world.
It’s crucial to grasp the more than a few types of crawlers that exist so you already know which kind you want to leverage for your private {industry} goals.
The 11 Most Not unusual Web Crawlers to Add to Your Crawler List
There isn’t one crawler that does all the art work for every search engine.
As an alternative, there are a number of web crawlers that evaluation your web pages and scan the content material subject matter for the entire engines like google available to consumers all over the world.
Let’s take a look at one of the vital most no longer atypical web crawlers in recent years.
1. Googlebot
Googlebot is Google’s generic web crawler that is in command of crawling web pages that can show up on Google’s search engine.

Even if there are technically two permutations of Googlebot—Googlebot Desktop and Googlebot Smartphone (Mobile)—most experts consider Googlebot one singular crawler.
It’s as a result of every observe the equivalent unique product token (known as an individual agent token) written in each internet web page’s robots.txt. The Googlebot particular person agent is solely “Googlebot.”
Googlebot goes to art work and usually accesses your internet web page every few seconds (till you’ve blocked it in your internet web page’s robots.txt). A backup of the scanned pages is saved in a unified database referred to as Google Cache. This allows you to take a look at out of date permutations of your internet web page.
In addition to, Google Seek Console is also another software website house owners use to understand how Googlebot is crawling their internet web page and to optimize their pages for search.
2. Bingbot
Bingbot was created in 2010 by the use of Microsoft to scan and index URLs to ensure that Bing offers similar, up-to-date search engine results for the platform’s consumers.
Similar to Googlebot, developers or marketers can define in their robots.txt on their internet web page whether or not they approve or deny the agent identifier “bingbot” to scan their internet web page.
In addition to, they be capable of distinguish between mobile-first indexing crawlers and desktop crawlers since Bingbot no longer too way back switched to a brand new agent kind. This, at the side of Bing Webmaster Equipment, provides website house owners with upper flexibility to show how their internet web page is came upon and showcased in search results.
3. Yandex Bot
Yandex Bot is a crawler specifically for the Russian search engine, Yandex. This is without doubt one of the largest and most popular serps in Russia.

Website online house owners may make their internet web page pages in the market to Yandex Bot via their robots.txt file.
In addition to, they may moreover add a Yandex.Metrica tag to precise pages, reindex pages throughout the Yandex Webmaster or issue an IndexNow protocol, a unique file that problems out new, modified, or deactivated pages.
4. Apple Bot
Apple commissioned the Apple Bot to transport slowly and index webpages for Apple’s Siri and Spotlight Concepts.
Apple Bot considers a couple of parts when deciding which content material subject matter to lift in Siri and Spotlight Concepts. The ones parts include particular person engagement, the relevance of search words, amount/top quality of links, location-based signs, and even webpage design.
5. DuckDuck Bot
The DuckDuckBot is the web crawler for DuckDuckGo, which supplies “Seamless privacy protection on your web browser.”
Website online house owners can use the DuckDuckBot API to look if the DuckDuck Bot has crawled their internet web page. As it crawls, it updates the DuckDuckBot API database with recent IP addresses and particular person agents.
That is serving to website house owners resolve any imposters or malicious bots taking a look to be associated with DuckDuck Bot.
6. Baidu Spider
Baidu is the primary Chinese language language search engine, and the Baidu Spider is the internet web page’s sole crawler.

Google is banned in China, so it’s crucial to permit the Baidu Spider to transport slowly your internet web page if you want to be triumphant within the Chinese language language market.
To identify the Baidu Spider crawling your internet web page, seek for the following particular person agents: baiduspider, baiduspider-image, baiduspider-video, and further.
In case you’re not doing {industry} in China, it will have to make sense to block the Baidu Spider in your robots.txt script. This will likely an increasing number of prevent the Baidu Spider from crawling your internet web page, thereby eliminating any likelihood of your pages appearing on Baidu’s search engine results pages (SERPs).
7. Sogou Spider
Sogou is a Chinese language language search engine that is reportedly the principle search engine with 10 billion Chinese language language pages indexed.

In case you’re doing {industry} throughout the Chinese language language market, this is another fashionable search engine crawler you want to learn about. The Sogou Spider follows the robot’s exclusion text and transfer slowly prolong parameters.
As with the Baidu Spider, in the event you occur to don’t want to do {industry} throughout the Chinese language language market, you will have to disable this spider to prevent gradual internet web page load events.
8. Facebook External Hit
Facebook External Hit, another way known as the Facebook Crawler, crawls the HTML of an app or website shared on Fb.

This allows the social platform to generate a sharable preview of each link posted on the platform. The title, description, and thumbnail image appear because of the crawler.
If the transfer slowly isn’t completed inside seconds, Facebook gained’t show the content material subject matter throughout the custom snippet generated previous than sharing.
9. Exabot
Exalead is a device company created in 2000 and headquartered in Paris, France. The company provides search platforms for consumer and mission shoppers.
Exabot is the crawler for their core search engine built on their CloudView product.
Like most serps, Exalead parts in every backlinking and the content material subject matter on web pages when ranking. Exabot is the individual agent of Exalead’s robot. The robot creates a “number one index” which compiles the effects that the hunt engine consumers will see.
10. Swiftbot
Swiftype is a convention search engine for your website. It combines “the best search technology, algorithms, content material subject matter ingestion framework, shoppers, and analytics equipment.”
When you’ve got a complicated internet web page with many pages, Swiftype offers a useful interface to catalog and index your whole pages for you.
Swiftbot is Swiftype’s web crawler. On the other hand, no longer like other bots, Swiftbot most simple crawls web pages that their shoppers request.
11. Slurp Bot
Slurp Bot is the Yahoo search robot that crawls and indexes pages for Yahoo.
This transfer slowly is essential for every Yahoo.com along with its partner web pages along side Yahoo Knowledge, Yahoo Finance, and Yahoo Sports activities actions. Without it, similar internet web page listings wouldn’t appear.
The indexed content material subject matter contributes to a additional custom designed web revel in for purchasers with additional similar results.
The 8 Commercial Crawlers search engine optimization Execs Need to Know
Now that you simply’ve were given 11 of the most well liked bots on your crawler tick list, let’s take a look at one of the vital no longer atypical business crawlers and search engine marketing equipment for pros.
1. Ahrefs Bot
The Ahrefs Bot is a web crawler that compiles and indexes the 12 trillion link database that fashionable search engine optimization software, Ahrefs, offers.
The Ahrefs Bot visits 6 billion internet websites every day and is regarded as “the second most lively crawler” at the back of most simple Googlebot.
Similar to other bots, the Ahrefs Bot follows robots.txt functions, along with we could in/disallows rules in each internet web page’s code.
2. Semrush Bot
The Semrush Bot lets in Semrush, a primary search engine optimization software, to collect and index internet web page knowledge for its shoppers’ use on its platform.
The tips is used in Semrush’s public backlink search engine, the internet web page audit software, the backlink audit software, link building software, and writing assistant.
It crawls your internet web page by the use of compiling a listing of web internet web page URLs, visiting them, and saving sure hyperlinks for long run visits.
3. Moz’s Advertising and marketing marketing campaign Crawler Rogerbot
Rogerbot is the crawler for the primary search engine optimization internet web page, Moz. This crawler is specifically accumulating content material subject matter for Moz Skilled Advertising and marketing marketing campaign internet web page audits.

Rogerbot follows all rules set forth in robots.txt information, so that you’ll be capable of decide if you want to block/allow Rogerbot from scanning your internet web page.
Website online house owners gained’t be capable of search for a static IP deal with to look which pages Rogerbot has crawled as a result of its multifaceted way.
4. Screaming Frog
Screaming Frog is a crawler that search engine marketing execs use to audit their own internet web page and resolve areas of construction that can affect their search engine rankings.

Once a transfer slowly is initiated, you’ll be capable of evaluation real-time knowledge and resolve damaged hyperlinks or improvements which can also be sought after for your internet web page titles, metadata, robots, copy content material subject matter, and further.
So as to configure the transfer slowly parameters, you will have to achieve a Screaming Frog license.
5. Lumar (in the past Deep Transfer slowly)
Lumar is a “centralized command middle for maintaining your internet web page’s technical smartly being.” With this platform, you’ll be capable of get started up a transfer slowly of your internet web page to help you plan your web page structure.
Lumar prides itself since the “fastest website crawler available on the market” and boasts that it will almost definitely transfer slowly up to 450 URLs in step with 2nd.
6. Majestic
Majestic mainly focuses on tracking and understanding backlinks on URLs.
The company prides itself on having “one of the most essential entire sources of backlink knowledge on the Internet,” highlighting its ancient index which has better from 5 to 15 years of links in 2021.
The internet web page’s crawler makes all of this data available to the company’s shoppers.
7. cognitiveSEO
cognitiveSEO is another crucial search engine optimization software that many pros use.
The cognitiveSEO crawler lets in consumers to perform entire internet web page audits that can inform their internet web page construction and overarching search engine marketing technique.
The bot will transfer slowly all pages and provide “a fully customized set of knowledge” that is unique for the end particular person. This data set may also have tips for the individual on how they can toughen their internet web page for various crawlers—every to affect rankings and block crawlers which can also be needless.
8. Oncrawl
Oncrawl is an “industry-leading search engine optimization crawler and log analyzer” for enterprise-level shoppers.
Shoppers can organize “transfer slowly profiles” to create specific parameters for the transfer slowly. You’ll save the ones settings (along side the start URL, transfer slowly limits, maximum transfer slowly tempo, and further) to easily run the transfer slowly all over again underneath the equivalent established parameters.
Do I Need to Give protection to My Web page from Malicious Web Crawlers?
Not all crawlers are excellent. Some would most likely negatively affect your web page pace, while others would most likely try to hack your internet web page or have malicious intentions.
That’s why it’s crucial to understand how to block crawlers from entering your internet web page.
By the use of putting in place a crawler tick list, you’ll know which crawlers are the great ones to seem out for. Then, you’ll be capable of weed all through the fishy ones and add them to your block checklist.
How To Block Malicious Web Crawlers
Together with your crawler tick list in hand, you’ll be able to resolve which bots you want to approve and which ones you want to block.
The first step is to go via your crawler tick list and description the individual agent and full agent string that is associated with each crawler along with its specific IP maintain. The ones are key understanding parts which can also be associated with each bot.
With the individual agent and IP maintain, you’ll be capable of have compatibility them in your internet web page knowledge via a DNS look up or IP have compatibility. In the event that they don’t have compatibility exactly, you might have a malicious bot attempting to pose as the true one.
Then, you’ll be capable of block the imposter by the use of adjusting permissions using your robots.txt internet web page tag.
Summary
Web crawlers are useful for serps and crucial for marketers to grasp.
Ensuring that your internet web page is crawled correctly by the use of the correct crawlers is very important to your enterprise’s just right fortune. By the use of keeping up a crawler tick list, you’ll be capable of know which ones to watch out for after they appear in your internet web page log.
As you observe the tips from business crawlers and make stronger your web page’s content material and pace, you’ll make it easier for crawlers to get admission to your internet web page and index the correct wisdom for serps and the patrons on the lookout for it.
The put up Crawler Listing: Internet Crawler Bots and How To Leverage Them for Good fortune seemed first on Kinsta®.
Contents
- 1 What Is a Web Crawler?
- 2 How Does a Web Crawler Artwork?
- 3 Compiling Your Crawler List: What Are the Different Kinds of Web Crawlers?
- 4 The 11 Most Not unusual Web Crawlers to Add to Your Crawler List
- 5 The 8 Commercial Crawlers search engine optimization Execs Need to Know
- 6 Do I Need to Give protection to My Web page from Malicious Web Crawlers?
- 7 Summary
- 8 17 Apps to Fortify the B2B Buyer Revel in
- 9 E-mail Advertising Analytics: 11 Perfect Metrics to Observe and How
- 10 Matt Mullenweg’s Involvement In The WordPress Group – The Wordsmith:…

0 Comments